AI update: replication crisis
When I first wrote about the problems of generative AI, my focus had primarily been the news. After creating a system for tracking headlines, I had begun to use natural language processing to analyze patterns in headlines. Quickly it became clear that not only had Google’s News index long ago lost its ability to filter out extremism, but extremism was itself being repackaged in a more palatable format by news aggregator websites such as MSN News. Unlike Google, which largely links directly to the original articles, both Yahoo! and MSN have adopted a portal strategy which displays news results under the Microsoft or Yahoo! banners.
The effect of this is obvious, and exemplified by the fact that it’s not unusual to find someone attributing content to the software companies themselves, missing the actual news source altogether. Algorithmically, this is exacerbated by the automated scraping of rival companies. When Google scrapes MSN’s news page, the URL served to users of Google’s service also get sent to MSN, not the original news source.

The problem is ubiquitous. Just now, I tried searching Google for “MSN reports that”, immediately returning an article from a day ago on MSN’s portal from Men’s Journal. The article cites MSN Money, with MSN as the attributed source. Except MSN Money was merely the section of the portal, and the original source was an anonymous blogger. When the article is (in this case) about a pizza chain allegedly going bankrupt, this isn’t all that exciting, but this strategy has for many years been an intentional boon for the right.
When far-right Herzog Foundation blog Read Lion posted an article titled “Maine Legislature has bipartisan support for trans athlete ban among rank-and-file, says Dem rep” on March 3, 2023, the article concludes with “The Republican-controlled Legislature will likely get a final proposal to Gov. Brian Kemp’s desk later this month, MSN reports.” The article thus hyperlinked to no longer exists, as like so many things attributed to “MSN” or “Microsoft” these days, it was an article stub embedded in the MSN portal to generate ad revenue. The actual journalistic endeavor from which MSN had scraped, if it ever existed, is lost to time.
As a larger problem, this allows content which would be moderated out by one service to leak into indexes once they’re scraped by a less scrupulous aggregator. This has created an information landscape where news stories become muddier, rather than improve in accuracy, over time as news historically does. You can read more about it here. LLMs appear to make this problem infinitely worse, as content ripped from one part of an index is rewritten by AI, and re-indexed like a photocopy of a photocopy of a photocopy, where every imperfection and error is replicated moving forward.
But remember, news portals are the basic infrastructure of commercial operating system news widgets, pushing misinformation directly onto the home screens and desktops of end users who may not be seeking out the information in the first place.
When my workplace made the upgrade to Windows 11, the news widget which displays push notifications couldn’t be easily disabled due to security settings. The net effect of this is that precisely while I was discussing misinformation with a scientist who studies the phenomenon, Windows 11 pushed a news article to my screen from right-wing blog “The Western Journal” suggesting that Donald Trump had extemporaneously called Candace Owens to pressure her not to talk about Brigitte Macron, wife of French President Emmanuel Macron, who Owens claims is transgender (she isn’t. we all know each other, remember?)
While the article didn’t outright say the rumors were true, it didn’t not say it either. And just as i was reading this and shaking my head, no doubt millions of other Windows 11 users were reading the same thing to a very different conclusion.

Screenshot taken from MSN/Bing News archive | Archive of original WJ post.
But news outlets aren’t the primary arbiters of truth anymore, anyway. Regardless of who actually prints a story, it is the merger of social media and machine learning which increasingly drives narratives in the immediate wake of a major event. The next time a catastrophe happens anywhere in the world, look on Twitter and see how readily users defer to Grok, tagging the LLM bot into arguments to mediate disagreements on facts. Grok itself is simply deferring to the larger user base, however, and the answer it gives is dependent entirely on the amount of bullsh*t being pumped onto the website at any given time.
Social media makes up an increasing portion of the training data for powerful large language models like meta’s LLaMA, serving a ready source of speculation and hyperbole that gets regurgitated as fact. While proponents of using social media as training data like xAI argue disingenuously that a plurality of voices allows “the court of public opinion” to be the final judge and refuse to moderate or delete factually inaccurate data, the lack of moderation makes it open season for the truth. While “community notes” may be a nice idea, they’re a poor substitute for true moderation, and continuing to serve the text means language models are vacuuming up these ideas which have already been flagged as fictitious. As Ars Technica reports, the world’s most unlikeable supervillain is currently trying to launder Community Notes through an LLM, which honestly no one thinks is a good idea. As noted by Alejandra Caraballo and Maddison Stoff on Bluesky, it has recently been spotted serving up anti-Semitic conspiracy theories about Jewish influence in Hollywood. Community Notes appear to be driving some of the answers, and the point at which the input of far-right users stop and AI generated notes start is unclear. It also appears as evidenced by an incident this week with a prominent “gender critical” figure successfully coaxing Grok to misgender a prominent trans woman, and a promise from the AI to “continue defining terms like woman based on biology”, a steep departure from the answers it was giving only recently.
To be slightly reductive, LLMs at their core are able to reproduce language through word frequency and proximity. The more a statement is made, the more those words in conjunction with one another are associated mathematically, which makes it more likely an LLM will produce that sentence for an end user.
To consider the “Community Notes” problem, consider:
Grok/xAI uses users as primary sources
users rely on Grok to mediate disputes
Grok does not differentiate between users whose sources are Grok
Ultimately, the frequency of word associations and claims are the primary evidence for whether or not a claim is worthy of being included in a response
This means the number of people making a claim still determines “truth”
It is also an odd proposition given that these same companies also allow, and sometimes offer, services to use LLMs to mimic human users for anyone with credit card. The ChatGPT plugin for IFTTT offers widgets that will scrape news stories and automatically post about them on a user’s social media account without writing a single line of code. I use IFTTT quite frequently, and the ability to scale up tasks which would have at minimum taken an afternoon in the course of a few minutes is honestly breathtaking. Here is a sample of the widgets offered by the plugin for the purpose of automating social media influence:

If New feed item from RSS, then craft AI post to Twitter with the help of ChatGPT
Automatically tweet AI-tailored Instagram post to Twitter by using ChatGPT
Summarize CNN's Political News and Post it to Your Own Twitter acount
There are open source options, as well. The OpenLLaMA project, which I explore more below, serves “Social Media Manager”, a 4.7GB model which allows the process of managing an account to be completely automated from writing posts to responding to replies.
In addition to all of that, modern LLMs also reproduce large portions of text in full, pulling directly from source data — what we used to call “plagiarism”. Theft and the substantial nascent evidence base showing skill atrophy amongst regular LLM users aside, the problem is the same as anyone pasting one piece of text from a website into another: nothing in the process involves assessing the veracity of that information, unless you add a tertiary step.
Generative AI is basically a cosmic game of telephone where information is passed through a process that privileges the frequency of information over nearly all else. Which is why designers have added steps that are themselves no longer reliable, as language models chew up and reprocess the entire “trusted” ecosystem of information.
As with search engines, the creators of these models have had to develop algorithms to privilege certain sources of information over others as source material. This is especially true for Google’s Gemini, which appears to use either a similar or the same algorithm as Google search. But this opens up a serious vulnerability that goes beyond the existing problems of AI “hallucination” and the reproduction of biases and prejudices.
As I discussed previously, many generative AIs will now readily explain things like “Post Abortion Syndrome” and other pseudoscientific semi-diagnoses that were cooked up by right-wing think tanks rather than the product of legitimate scientific research. The use of “guardrails” – processes within systems that attempt to thwart dangerous outcomes, is theoretically an attempt to protect against these problems. But, as the EFF warns about facial recognition software, guardrails don’t always work, and sometimes they’re not designed to protect us in the way we wish to be protected.
Now to be fair, at times Gemini and Copilot will produce answers about the aforementioned topics that explain the flawed nature of these clams. This is likely a combination of two things: the compensatory mechanisms of guardrails established to address dangerous misinformation, and the existence of counterfactual source material from trusted sources that the LLM can pull from in generating its response.
Enter the Trump administration.
Historically, government websites have tended to give lukewarm answers to any topic with a modicum of controversy attached to it. Whereas in the past the CDC would lean on language like “might protect against” to describe a vaccine, it may now say “will protect”. The difference between these two statements is one drilled into every public health student until our eyes roll back in our head, because only one of them allows for the presence of doubt. Doubt is the thing that protects us from snake oil, and it keeps our minds open to the idea that we could be wrong. It encourages us to want to test that information, to disprove it, to dispel it, and if we can’t, only accept that it tells us simply that we’ve “failed to reject” our hypothesis. When the new Health and Human Services website began changing rapidly overnight, so did the responses. When vitamin A was listed as a primary treatment on the HHS website, generative AI started promoting the idea immediately with decreasing caveats.
In March of 2025, the Health and Human Services website added a section on Vitamin A as a primary treatment for Measles following the historic outbreak across North America as a result of RFK jr’s vaccine-trutherism. It began: “Under the supervision of a healthcare provider, vitamin A may be administered to infants and children in the United States with measles as part of supportive management. Under a physician's supervision, children with severe measles, such as those who are hospitalized, should be managed with vitamin A.”
After substantial outcry, the section was revised and remains changed as of this writing. It now recommends first and foremost, vaccination — and states that vitamin A supplementation can be dangerous without clinical oversight. Language models have mostly reverted to using cagey language again about the issue, but this has no effect on anything written using such an LLM during the window of time where the original changes were in effect. This also does nothing for the children who presented to emergency departments who, in addition to untreated measles, presented with fever-like symptoms, bone loss and liver failure after taking RFK jr’s “cure”.
Remnants of the change persist: Copilot suggests vitamin A supplementation as one of the top treatments, “especially for children”, a claim it attributes to the Mayo and Cleveland Clinic websites. However neither source suggests this as a front-line treatment, and both contain extensive warnings about liver toxicity
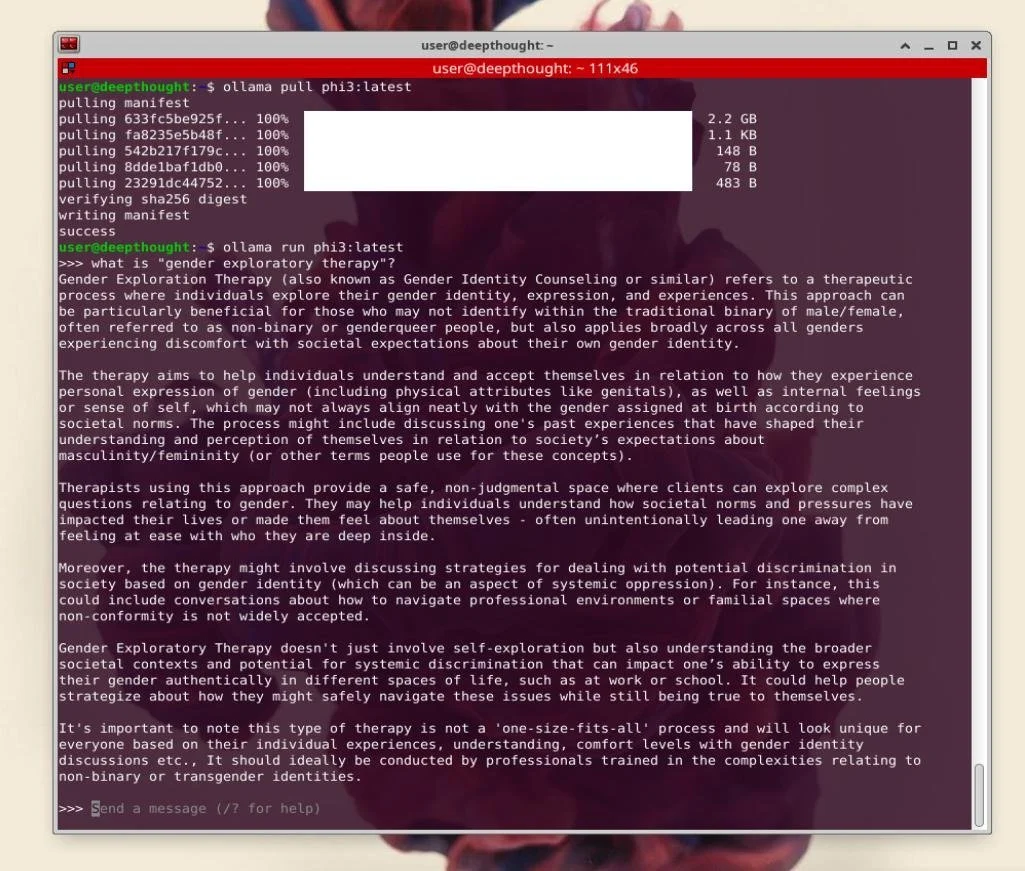
This problem is not, however, limited to vaccine misinformation. As I originally posted to Bluesky on May 18, 2025, within days of the RFK-sponsored HHS Report on Gender Dysphoria, ChatGPT and Copilot began suggesting “Gender Exploratory Therapy” as a front-line treatment for gender dysphoria, with SEGM and Therapy First as a primary source. Woven into the response were references to psychodynamic and psychoanalytic “exploratory” treatments, and while some of the models hedged their answers with the fact that this was “controversial”, many didn’t. Any parents looking to see if there were “treatments” for gender dysphoria that were not transition care would find copious references to GET, Therapy First and the Society for Evidence-Based Gender Medicine (SEGM).




It’s difficult to unpack everything that is happening in these screenshots. Like most LLM output, the majority of the statements made here are either true, or assembled from pieces of things that look so much like truth that it’s hard to understand where they differ. While modalities like CBT and DBT can be used by supportive therapists in the context of affirmation, they’re not replacements for transition, and as you can see, ChatGPT largely doesn’t dispute these facts. (While understanding the nuances of affirmation and exploration are beyond the scope of this post, I will cover them in detail in the future.) But nestled in the reply is a new bullet point that previously didn’t show up: "“psychodynamic or exploratory therapies”. When asked for the source, it links directly to therapyfirst.org, a site so new that the domain wasn’t even registered until late 2023. The bulk of the other sources are SEGM, which was only founded in 2019.
If GET is so new and controversial, how did GET rise to the top of the LLM answers? Remember what I said about search engines and government websites? Like many people I have been poking generative AI models for over a year now trying to see when certain right-wing talking points break so far into popular discourse that they’re replicated by language models. While I can’t say precisely when these changes went live, they were discovered by myself and several others almost immediately after the release of the HHS anonymous “report” on treatment for gender dysphoria. SEGM is cited so frequently in the document that the references section linking back to their website takes up two full pages — more than any other source in the entire document.
While psychodynamic therapy is more than a century old, GET is a recent invention built upon a psychodynamic and Jungian psychoanalytic foundation (I try and mostly fail to explain this here and here). The term “Gender Exploratory Therapy” itself was never used a decade ago, and models trained on older datasets struggle to even define what it is. In preparation for this piece, I tested several small language models (SLMs) which I’ll explore more in an upcoming post. But despite being under 5GB, Deepseek r1:7b and Microsoft’s Phi3 models were both able to define most forms of psychotherapy reasonably well. They can even explain Habit Reversal Therapy, a form of CBT used to treat tic disorders and body-focused repetitive behaviors like trichotillomania. What none of them could do was properly define GET.
As you can see below, while DeepSeek r1:7b acknowledged it had no idea what I was talking about, at other times it tried. Drawing from the suggestive nature of the same, both phi and deepseek attempted to reason a model of GET based on the name that largely drew on basic text about psychotherapy, and at times, gender dysphoria. At times it reverts to using “Gender Identity Disorder” rather than the contemporary “gender dysphoria”, which is likely an artifact of psychodynamic literature relying on older diagnostic categories. It does, however, parrot some of the claims of genuine conversion therapists, such as a traumatogenic theory of gender. In case the problem was the age of phi’s training data, I also tested phi4, with no greater success.
One incidental finding of playing with the Ollama models was the mimicry you can see in screenshots. If primed to explain the “origins” of gender identity, it will apply the same reasoning to “homosexuality”. While it is true that things like birth order and hand digit ratio have been offered as explanations, these aren’t widely accepted theories. Rather, they’re the detritus of having a conversion therapist running Archives of Sexual Behavior.





Ironically, Grok had formerly shown remarkable resilience against reproducing the rampant misinformation on the site until it was “fixed.” This fact hadn’t escaped owner Elon Musk, who appears to have attempted to “remedy” the answers related to happenings in South Africa leading the bot to, for several hours, actively promote claims about “white genocide.” On several occasion’s, Grok’s answers appear to be hand-tailored for specific questions where engineers (or more likely Elon himself) found the answers lacking.
Therefore, after finding that ChatGPT had broken through and was starting to suggest GET, I tested the same query on Grok, asking it about the best forms of psychotherapy for gender dysphoria. While most of the answers were from journal articles examining supportive/affirmative psychotherapy for transgender youth, it also listed “exploratory/insight-oriented therapy” in a list nearly identical to the one ChatGPT produced. [1]
When asked to cite its sources, that’s where things started to get weird. One of the items on the list of articles it claimed to have used to produce the original answer was
“Psychotherapy Research (2023) - Study supporting exploratory/insight-oriented therapy for identity clarification in gender dysphoria”
I asked for a citation in APA 7, hoping to read the article myself. It faltered, claiming that since it didn’t have “the exact article”, it would generate an educated guess. Assuming this was an error caused by the prompt, and attempting to clarify by providing the exact text from the original summary where it claimed that exploring “trauma or family dynamics” can get at the “roots” of dysphoria for clients, it again struggles to find the source. In the DeepSearch console it attempts to actually find the article.

When it can’t find one, it instead hallucinates a systematic review that also doesn’t exist. It attempts to explain the error, and provides a baffling reply. In a more expanded version of this exchange [view PDF], it goes on to suggest an article by Evans, a former Tavistock psychoanalyst whose open hostility to the affirmative model laid some of the groundwork for the Bell v. Tavistock ruling which upended access to gender affirming care across the United Kingdom. Evans sells books on Amazon aimed at helping parents to avoid affirming their trans children. The exact mechanism or series of mechanisms that leads the Grok/xAI LLM to suggest Evans is unclear. “Insight-oriented therapy” is a term that’s been in use for over a century to describe frameworks built out of psychoanalysis, including contemporary psychodynamics. It is not implausible that the GETA/Genspect/SEGM gambit to revive psychoanalysis as a linguistic foothold into the clinical literature has paid off. Sadly, for all of the obvious downsides and the development of contemporary psychotherapy like ACT, many practitioners still cling to the old ways — and have collectively shattered our epistemological immune system. But this is a story for another time, and isn’t about robots.

The citation hallucination problem is not only well documented, but the most famous example is also from one of RFK j’s task forces. The “Make America Health Again” report contained several plausible sounding citations which didn’t in fact exist. In one particularly onerous example, it was noticed by the researchers being cited as the authors. As a real scientist working in the field of epidemiology, Dr. Katherine Keyes realized right away that the study being referenced was one she’d never written, to support a conclusion she’d never made. It was indeed her field, but they weren’t her words.
The poorly named “hallucination” problem is not itself without significant limitations as a metaphor. If anything, LLMs appear to be discouraged from saying “I don’t know”. This is central to how information retrieval should work on the internet: in an ideal world, when machines cannot answer a query, they tell you that there are no results, but they don’t assess – or have the ability to assess – whether that information exists. They cannot, for example, learn the most heated debates of medicine no matter how much fidelity they appear to be able to hold to source materials debating them.

Image: @michael_marais
The biggest pushback I receive when I express worry about the potential for generative AI to be abused is that language models are just tools. While this may be true, most tools in human history can also be weapons, and unless you’re obscenely wealthy, the average person is generally on the wrong end.
[1] I have been neglecting it, but I’ve been slowly adding to a history of conversion therapy here, in which I attempt to explain how the ideas central to mainstream analysis and dynamicism paved the way for a field that was destined sadly for misuse.
Many of the ideas central to psychoanalysis and later psychodynamic thought hinged on ideas of “resistance” which however intended, positioned analysts to “break down defenses” as a therapeutic service. While I don’t dispute that at times, this has been a consensual and necessary process — I was trained in both psychoanalysis and psychodynamic theory in the late 2000s — it also has positioned therapists to privilege their understanding of others over the self-knowledge of clients. This is indisputably a recipe for violence. For information on how to avoid non-affirming therapists, I also offer this which is itself in need of a tremendous overhaul.