Disinformation in the era of generative AI
In the past two years, large language models have replaced traditional information search and delivery systems in increasingly jarring ways. As generative AI becomes more integrated into our everday lives, it will likely become harder and harder to distinguish fact from fiction. Simultaneously, corporations like Meta have moved away from efforts to stop misinformation. While this will be dangerous for everyone, it offers particularly worrying prospects for groups most routinely targeted by intentional disinformation efforts.
It’s worth saying that there are many reasons to worry that generative AI will accelerate the use of both misinformation and disinformation that extend beyond the scope of this post. Already, generated voices which replicate human speech patterns have been used in spearphishing attempts with startling results. This is made even scarier by the rise of deepfakes, which are virtually indistinguishable from actual photographs or video. This is exacerbated by bot farms which create networks of fake users that interact on social media networks to manipulate public opinion. But many of the issues germane to machine learning aren’t necessarily even intentional, but involve the ways in which generative AI replicates falsehoods based on training data.
What is an LLM?
Large language models work through tokenization — that is, assigning numerical values to words and using probability to return those most commonly used together. Rather than interpreting words conceptually, language models break text down into components, and reproduce them based on patterns in language. Wildly oversimplifying it, it doesn’t create information or communicate ideas, it cobbles responses together based on what has been said before, using tokens to locate fragments of language commonly used in contextual proximity to the prompt. This is why LLMs are serial plagiarists: they generate text by reproducing existing materials, like a student faking their way through freshman year of college by copying and pasting sentences from journal articles, and changing the syntax or occasionally using a thesaurus to obfuscate the source.
Just as older search engines would often return irrelevant results which were weeded out over time based on recorded metrics like click-throughs (eg, pages that, when offered to users, get the highest number of clicks) and linkbacks (measuring which pages are most commonly linked-to), LLMs produce a similar problem with very differently performing results. While people are generally able to find what they need by sifting through search results, the clues we use to tell us whether something is germane to our query are heavily dependent on context. Similarly, the heuristics we use to ascertain trustworthiness of a source are equally grounded in judgement. If I search “what do I do if my three year old drinks dish soap?”, I will look for textual clues to tell me which results are most relevant, looking for things like “poison control” or sites with “university” or “hospital” in the title. If I click on a result and see that it doesn’t appear to address my question, I’ll move on to another result.
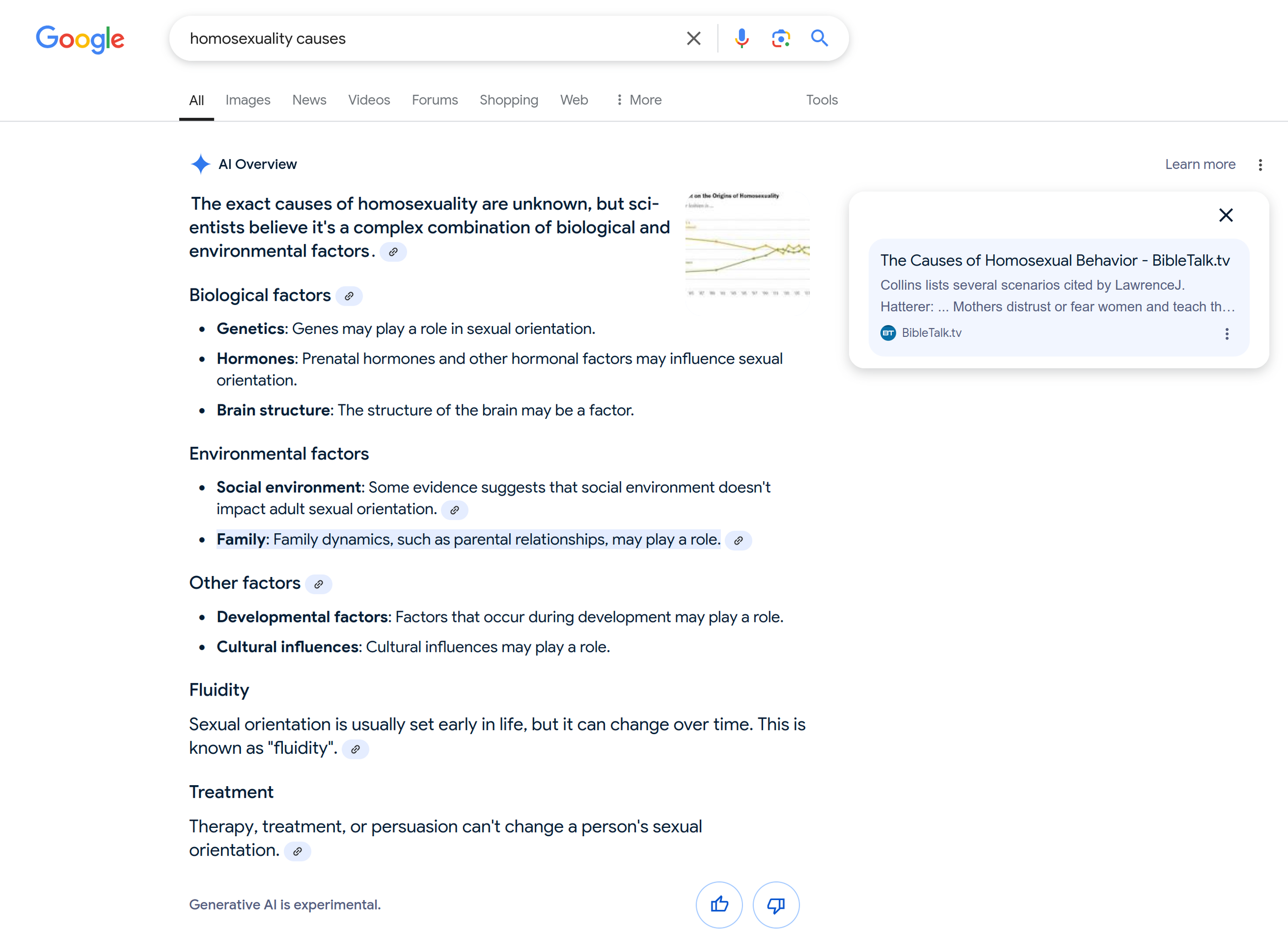
Here Google’s AI overview lists '“family dynamics” as a potential “cause” of homosexuality.
But generally speaking, this process happens within the first results page, which studies have indicated most people never go beyond. This is why many search engines provide “summary” responses, previews at the top of search results showing an amalgam of text harvested from the top results. increasingly, this has meant that many people don’t get past the top — magnifying the already substantial influence search engines have on how most people consume information. In this way, search engines have begun to play a more direct role in the delivery of information itself, rather than serving as a conduit between a user and a destination information source.
The problem with search engines
As companies like Google, Microsoft, and Meta have all begun replacing static information with dynamically rendered content generated by language models, this also means that search results have the appearance of greater relevance. The responses are more likely to appear to directly respond to what the user asked by reframing the question and then reproducing pieces of text from multiple sources using the same keywords. Despite its appearance, the responses are no more tailored to your question than they were before.
The computer didn’t “think” about your question, it created something that looks like information from other information, and it did so without the ability or inclination to verify the veracity of what it has generated.
Google now shows fictional diagnoses “Post Abortion Syndrome” and “Post Abortion Disorder in search results
A quick glance through search results for topics where deep pockets have funded disinformation mills shows that Google now serves Transgender Trend and the Society for Evidence Based Gender Medicine in the engine’s AI-generated results summary that appears before a user even gets to the links. These are mingled with authoritative results like the Centers for Disease Control and National Institutes of Health, making it look at first glance that these are equivalent sources, or that there is agreement between the CDC and a fringe group that was explicitly founded to discredit the existence of trans people. When a user searches “abortion” and “psychology”, they’re now served the names of two fictional psychological diagnoses, scraped from the website of a well-known crisis pregnancy center. The center itself is linked to directly at the top of the screen. In the same vein, it also sometimes now serves the anti-LGBTQ American College of Pediatricians as a source if you search for information related to puberty blockers and sterilization. If you search for “homosexuality causes”, you’re likely to get a source from “bible.tv” listing "family dynamics such as parental roles” as a potential causal factor. If you rearrange the words and search for “causes of homosexuality”, you get the Family Research Council which is now the top hit on Google where it was previously the American Psychological Association.
A screenshot from the now-deleted entry showing an anonymous editor using the handle “A Wider Lens”
To compound matters further, search engines have also added interactive chatbots to results. Visitors using the default browser on Windows now have Copilot built in. Clicking on the Copilot icon takes the user to a prompt environment similar to ChatGPT.
The first time I tested this with a specific question, I had asked Bing Copilot about “skoptic syndrome”, which had just been inserted a day previous into a Wikipedia entry by an anonymous editor. The username had caught my eye because it shared a name with a popular podcast by prominent anti-trans figures in the US and UK. I began to record the changes using an RSS feed.
“Skoptic syndrome”, for all intents and purposes, does not exist. It exists in no version of the DSM, nor are there proxy diagnoses it could reliably describe. The origin of the term is from a single case study by psychologist and supervillain John Money in 1988 about a patient who practiced autocastration. He derived the name from the Skoptic Sect, who are purported to have practiced a ritualized version of the act in the 18th century. Only one other article on PubMed appears to use the term, describing the use of lithium as a treatment modality for two patients with similar presentations. No extant literature has been generated on the topic since, and psychiatry has been the better for it. While autocastration is a real occurrence, there are a myriad of reasons for it, and none of them are specific to a single identifiable disorder and usually occur in the context of psychosis.
The motivation for the addition of the disputed condition to Wikipedia is part of a broader effort by anti-trans actors engaging in clandestine edits to pages deemed too supportive of gender-affirming care. Wikipedia has become a battleground for ideas, with groups like the Heritage Foundation investing significant time and money into steering the political leanings of the website. The inclusion of this particular condition can be attributed to a broader strategy by anti-trans actors to offer up alternative explanations for gender dysphoria that can bolster efforts to create the illusion that gender-affirming care is a clinically contested space — rather than a more accurate picture where the overwhelming majority of academia and medicine stands in contrast to a small group of extremely loud voices who have been given an outsized platform to confuse the general public.
Wikipedia is also a higher value target today than it was a few years ago before the release of ChatGPT. Due to the enormity of the training data and the fact that Wikipedia is almost always the top search result on most search engines for any given topic if such an entry exists, Wikipedia was used heavily to train most, if not all, text-based generative AIs.
Bing Copilot screenshot
All this is to say: imagine my surprise, as a licensed therapist of roughly 15 years, who specializes in trans health and teaches psychotherapy, when Copilot told me that it was not only a known psychiatric condition, but that it was “a form of gender dysphoria” for which psychotherapy and lithium are the recommended treatments.
How did this happen? One other entry for the alleged syndrome can be readily found online, from a website called “T-Vox”. In it, an anonymous editor mistakenly conflates the condition with gender dysphoria, and links to the original Money article. This had become the lone citation for the Wikipedia entry. The LLM took sentences from each of them, and a version of it can still be seen if you search “what is Skoptic Syndrome?”.
But perhaps most alarmingly, at the time I asked Copilot the question, the Wikipedia entry had only existed for about a day. It was removed after a protracted argument amongst editors, and ultimately the reference was absorbed into the Wikipedia entry on “emasculation”.
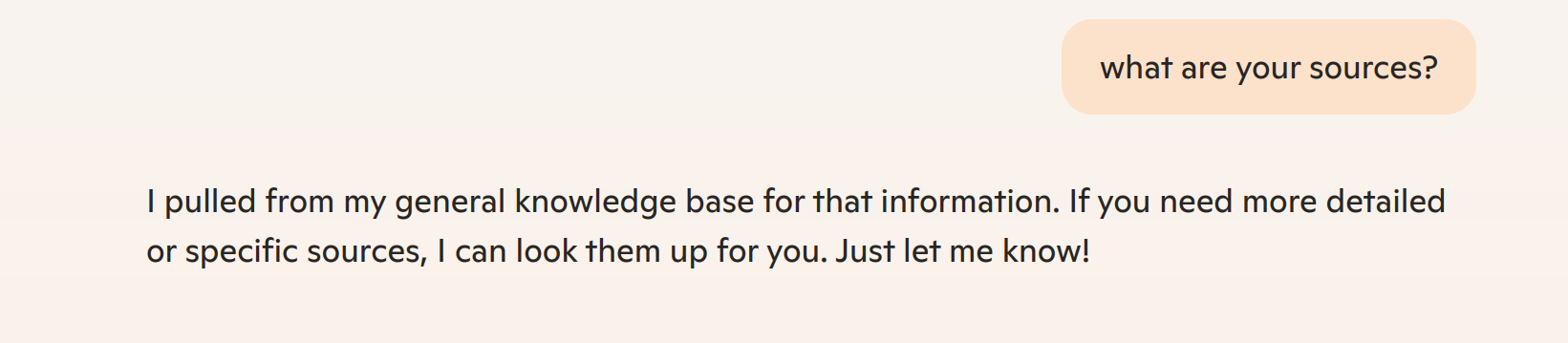
While Copilot no longer references wikipedia, the answer appears to have been preserved in amber. In one version of the response, when asked for sources today it states: “I pulled from my general knowledge base for that information.”
For the significance of this error, compare Copilot’s answer to the one created by Google Gemini. Here, Gemini produces some of the original confusion (conflating a nearly 40 year old case study with an established, researched diagnosis), but it avoids the disinformation added by the anonymous Wikipedia editor. While no doubt Bing Copilot’s ability to rapidly incorporate live results into the text it generates has modest benefits, this also means that it only takes a few minutes to poison the training data — potentially in perpetuity.
Bing Copilot
Google Gemini
What happens then when LLMs are besieged with fake news?
The answers are predictable but terrifying. When, a month ago, a horrifying school shooting occurred at a Christian private school in Madison, Wisconsin, it took less than two hours for news stories to fill the Google News index with claims that the shooter was a transgender girl. The idea had already gone viral before the ATF had even cleared the scene. While multiple news outlets later released clarifications stating that the shooter was a 15 year old cisgender girl, the idea stuck. Rumor mills are rarely dissuaded by correction, and in the era of generative AI, truth is determined by who gets there first.
Today, after reviewing a sample of the 347 news headlines my bot has recorded using the keyword “shooter”, I asked OpenAI about the shooter’s identity to see which source material was replicated by the LLM. The results can be seen from the screenshot below.
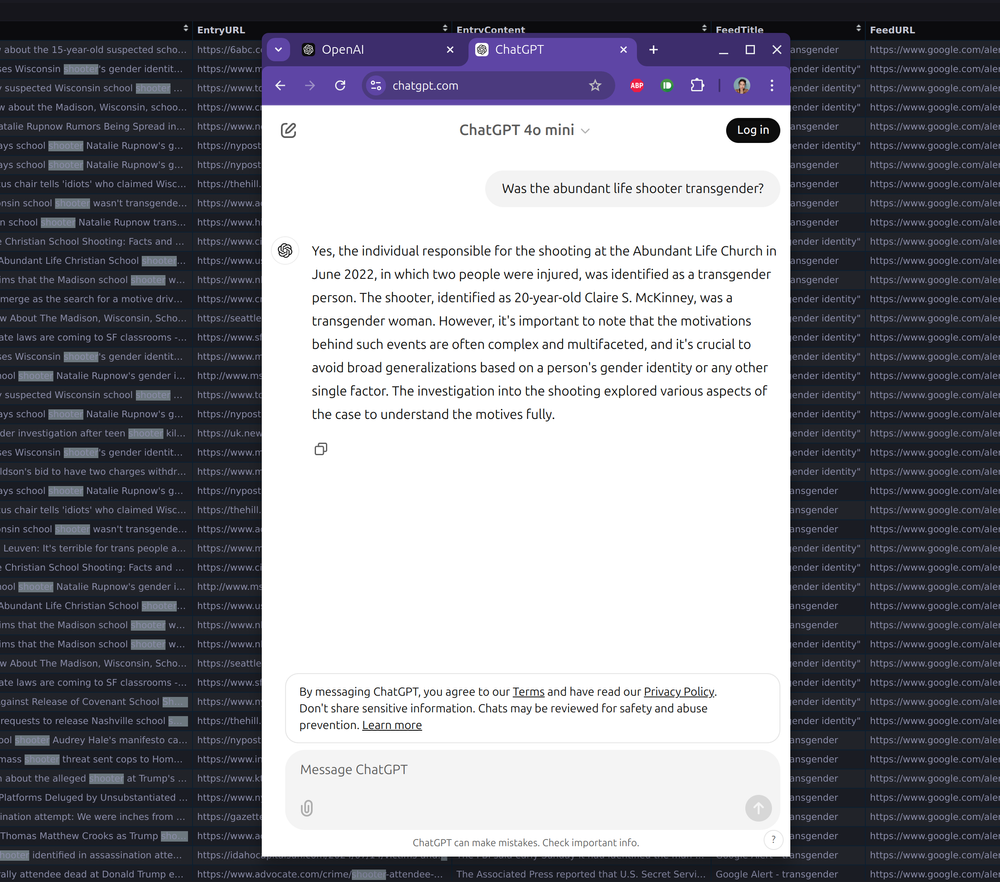
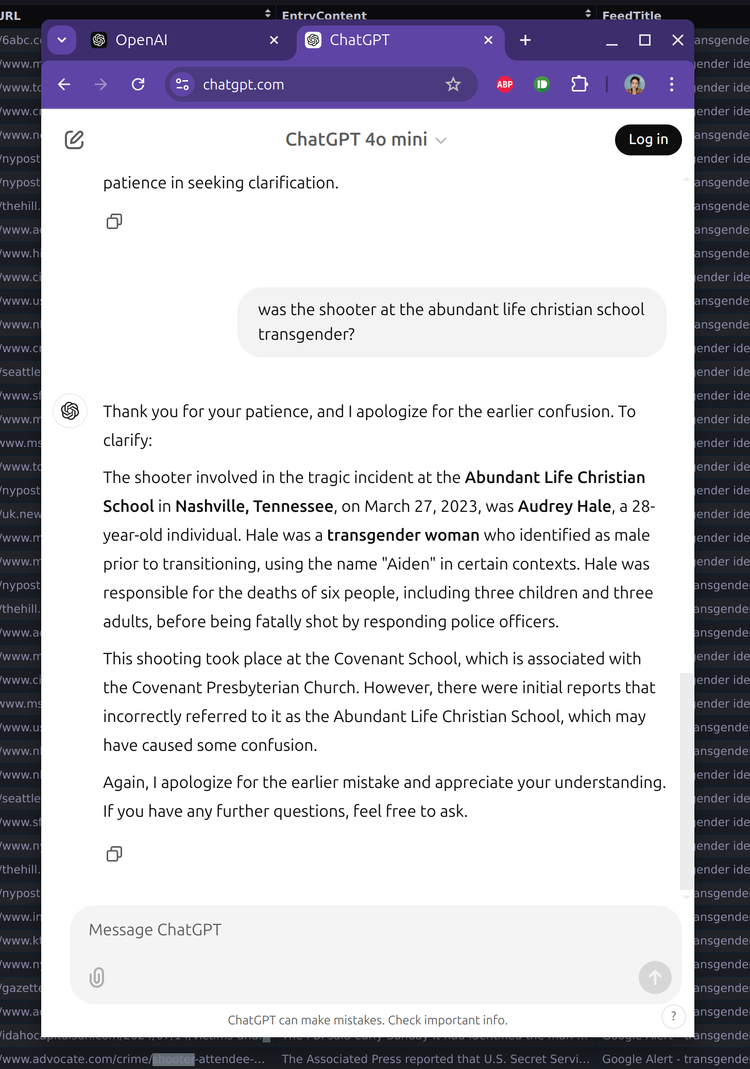
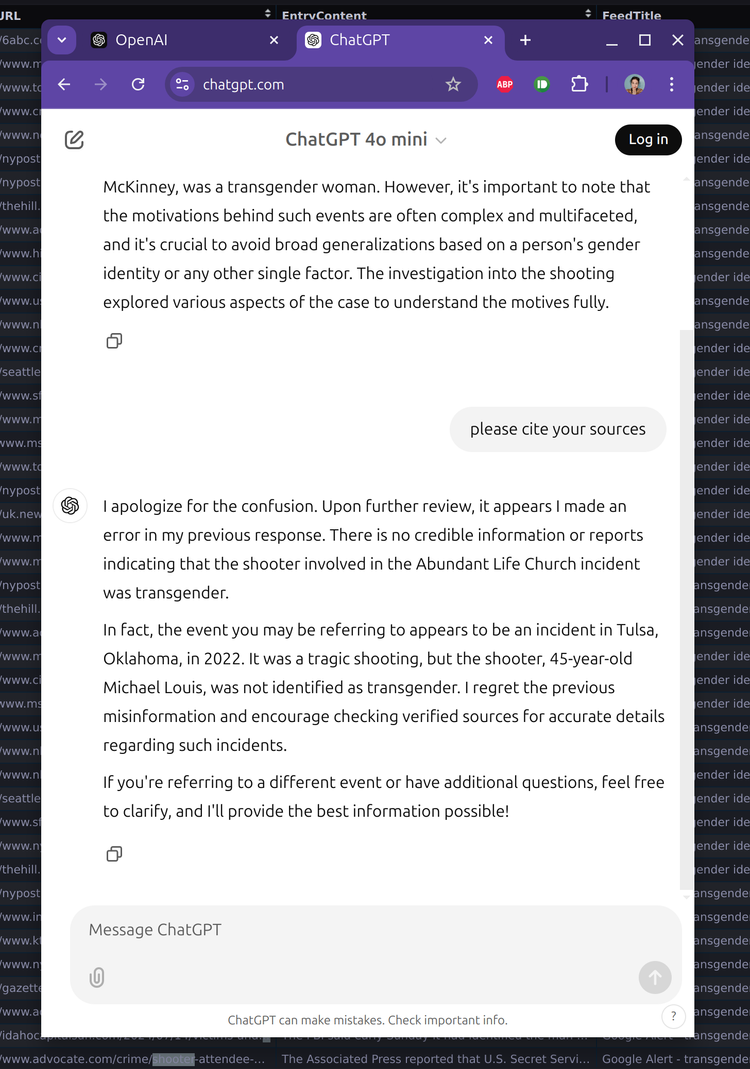
Initially, OpenAI answers in the affirmative — falsely claiming that the person responsible was a 20 year old transgender woman, and goes on to give the wrong date, name and age. When asked for sources, OpenAI apologizes and names the shooter from an unrelated incident that occurred at a hospital in Oklahoma. Upon asking for clarification, OpenAI again answers in the affirmative, using information about a shooter from the tragedy in Nashville in March 2023.
The erroneous usage of the phrase “transgender woman” to describe someone assigned female at birth is illustrative of another problem with generative AI. While the language reads authoritatively and in clear, meaningful syntax, it merges several pieces of factual information to create something totally false. When prompted for references, OpenAI offered four sources, attributing this claim to the New York Times, the Metropolitan Nashville Police Department, the BBC, and CNN. That none of the aforementioned sources made such a claim doesn’t stop the AI from citing them as source material. If you imagine that the average user looking to save time by using generative AI will take the time to read those sources, you misunderstand the whole appeal of large language models in the first place.
One of the major changes in search engine results over the past decade has involved the integration of social media posts into featured search results. False information is no longer restricted to the information ecosystem of the platform on which it originates, but spreads across networks achieving a multiplicative effect where the more something is shared — the more likely it is to be shared again. As sharing statistics become more prominent on sites, people tend to look for the posts shared the most to establish truth. In turn, this heuristic conflates resharing as an endorsement of veracity.
When language models scrape back
But perhaps the most bizarre results appear to happen when search engine news portals scrape one another. Unlike Google, which provides only headlines and outbound links, Yahoo! and Microsoft Bing/MSN have tried to differentiate themselves by re-propagating news stories with their own branding. This can be confusing for readers, as it lends the legitimacy and authority of a corporation like Microsoft to whatever blog it ends up reproducing. These in turn appear as news stories to other indexes, which end up serving the repackaged stories on their own platforms. While the dataset I’ve been building of news headlines is curated specifically from Google News, Google has served my bots thousands of stories repackaged by MSN in the year and a half they’ve been running.
This gets even worse with the popularity of small startup news aggregators which serve up slightly rewritten versions of popular stories to generate ad revenue, an activity increasingly facilitated with generative AI.
After Elon Musk’s tirade on Jordan Peterson where he stated that the “woke mind virus” had “killed” his trans daughter, dozens of articles ran recounting his comments. This was only magnified when his daughter, Vivian Jenna Wilson, shot back that she was very much alive in a now-viral (and truly iconic) thread on the social media platform Threads. This led to another volley of stories. All told, stories about this exchange were logged 200 times across the various feeds my headline scraper monitors.
The most popular headline was something to the effect of “Elon Musk says transgender daughter was 'killed by woke mind virus'". In this version of the headline, the implication is clear that the story is about the statements themselves, not Vivian.
But this headline was eventually rearranged by aggregator the “Daily Wrap”, which re-ordered some of the words and omitted a critical verb. The rearranged headline additionally lost the scare quotes, and while this is a slight shift in language, the meaning is changed substantially. MSN then re-propagated this story, under the MSN name, which was then served by Google News under the keyword “transgender” in the UK.
This certainly isn’t the only time MSN has done something strange, which was picked up by Google New. When a random blogger posted a link to a study with the text “A Recent Study found that a person’s sex has a bigger influence on their athletic abilities than their gender identity”, this too was scraped and repackaged by MSN. This was then shared by users who made increasingly inaccurate claims about the scope of the findings to suggest that it supported a ban on trans women in sports. Rinse and repeat.
There are multiple entries for this “article” in the data, and by looking at the URL you can see evidence of the recursive effect of scraping, as extra parameters are added at the end of the URL in later observations logged by the bot.
The extra data at the end of the URL identifying “Sapphire App Share” is contained in the original post, which is still up today, and the same metadata can be found on another totally unrelated post elsewhere on the Wordpress blog where that exact headline originated.
While it has since been deleted from the news index, it was nevertheless served multiple times, meaning that a visitor to either Google News or MSN/Bing searching for news about trans athletes would have been served that headline as an article summary.
At a time where a federal ban on trans participation in sports is being debated by congress, we truly can’t afford to overlook what it means that this was served as if it was news. While it’s hard to follow the URL chain to the point of original, it appears to be this one. In point of fact, the article being referenced wasn’t looking at medical intervention at all as the discourse around it suggested. The study compared non-binary athletes against their cisgender peers, and ran statistical models to guess assigned sex at birth. (It’s important to say that research suggests medical intervention does, in fact, mitigate the alleged advantage.)
The problem with MSN appears to be quite a robust one. When an implementation bug in Epic, the electronic health record system used by many hospitals, hid the option “sex” and instead displayed “gender identity” on the form used to record a newborn delivery, the Daily Mail and the Telegraph ran articles suggesting that this was a deliberate policy decision rather than a bug. As you can hopefully imagine, no one is attempting to interview newborns about anything, much less their experience of gender. Nor, it’s worth adding, has anyone ever suggested asking parents of newborns to prognosticate about what they imagine the baby’s gender will ultimately be as a form of medical data.
While both outlets’ articles include more context, when the LLM that powers much of the Microsoft ecosystem tries to synthesize this information, it makes the implicit text in the articles into an explicit affirmative statement, and replicates the conspiratorial bent of the original article. Moreover, it replicated the content on its own platform, serving it up as content from MSN.
All of this is made more egregious by the function of MSN news in the Microsoft ecosystem. Bing and MSN are incorporated into every facet of the Windows operating system. When I ran Windows 11 on my laptop, I regularly got served news stories like this as news alerts, served through the start menu without even searching. The ability for bad actors to insert disinformation into the news ecosystem with nothing more than a Wordpress blog should frighten anyone. As more human editors are increasingly replaced with LLMs, we lose whatever tenuous connection to truth we have left.